

파일 시스템은 데이터를 디스크에 영구적으로 저장해야 하지만, 시스템 충돌(Crash)이나 전원 차단은 예고 없이 발생한다. 이 장에서는 파일 시스템이 어떻게 이러한 위기 속에서 데이터의 일관성을 유지하는지 깊이 있게 다룬다.
1. 크래시 일관성 문제의 핵심 (The Problem)
파일 시스템 업데이트는 단일 작업이 아니다. 책의 예시인 '파일에 하나의 데이터 블록을 추가하는 상황(Append)'을 가정해 본다. 이 작업을 완수하려면 디스크 상의 세 가지 구조체를 수정해야 한다.
- data bitmap: 새로운 블록이 할당되었음을 표시한다.
- inode: 파일 크기를 갱신하고 새 블록을 가리키는 포인터를 추가한다.
- data block (Db): 실제 사용자 데이터를 쓴다.
문제는 디스크가 이 세 가지 쓰기 작업을 동시에 '원자적(Atomic)'으로 처리할 수 없다는 점이다. 만약 작업 도중 충돌이 발생하여 일부만 기록된다면, 파일 시스템은 일관성이 깨진 상태가 된다.

위 이미지는 Inode와 Data Bitmap은 업데이트되었지만, 실제 Data Block 기록 중에 충돌이 발생한 상황을 보여준다. 이 경우 파일 시스템은 존재하지 않는 쓰레기 데이터를 가리키게 된다.
발생 가능한 시나리오
- 데이터 블록만 쓰인 경우: 파일 시스템 입장에서는 아무 일도 일어나지 않은 것과 같으나, 데이터는 디스크 어딘가에 유령처럼 남는다.
- 메타데이터(Inode/Bitmap)만 쓰인 경우: 파일 시스템은 데이터가 있다고 믿지만, 실제 블록에는 과거의 쓰레기 데이터가 들어있어 메타데이터 부패(Metadata Corruption)가 발생한다.
- 비트맵만 업데이트된 경우: 해당 블록은 사용 중으로 표시되지만 어떤 파일도 이를 소유하지 않는 스페이스 리크(Space Leak)가 발생한다.
2. 고전적 해결책: FSCK (File System Checker)
초기 시스템은 충돌을 막으려 하지 않고, 문제가 생긴 후 고치는 방식을 택했다. 그것이 바로 FSCK다. FSCK는 시스템 부팅 시 실행되며 디스크의 모든 메타데이터를 전수 조사한다.
FSCK의 상세 점검 단계
- 슈퍼블록 점검: 파일 시스템의 크기가 합리적인지 등 기본 정보를 확인한다.
- 프리 블록 비트맵 점검: 모든 inode를 스캔하여 어떤 블록이 할당되었는지 확인하고, 이를 바탕으로 비트맵을 강제로 재구축하여 일치시킨다.
- Inode 상태 및 링크 카운트: 파일과 디렉토리 연결 구조를 전부 확인하여 inode에 기록된 링크 수와 실제 참조 수가 맞는지 교정한다.
- 중복 할당 확인: 두 개의 파일이 동일한 블록을 가리키는 경우를 찾아 해결한다.
- 디렉토리 체크: 디렉토리 구조 내의 .과 .. 포인터가 올바른지 확인한다.
한계점: 디스크가 수 테라바이트(TB) 규모로 커지면서 모든 블록을 스캔하는 데 수 시간이 걸리게 되었다. 이는 가용성 면에서 치명적인 결함이 된다.
3. 현대적 해결책: 저널링 (Journaling/WAL)
저널링은 "Write-Ahead Logging" 개념을 파일 시스템에 도입한 것이다. 실제 데이터를 수정하기 전, 수행할 작업에 대한 노트를 먼저 남기는 방식이다.
데이터 저널링의 5단계 과정 (Data Journaling)
책에서는 이를 아래와 같은 단계로 상세히 설명한다.
- Journal Write: 트랜잭션의 시작을 알리는 TxB(Transaction Begin), 수정될 비트맵, inode, 그리고 실제 데이터(Db)를 저널 영역에 쓴다.
- Journal Commit: 트랜잭션의 끝을 알리는 TxE(Transaction End) 블록을 쓴다. 이 블록이 디스크에 안전하게 기록되어야 트랜잭션이 완료된 것으로 간주한다.
- Checkpoint: 이제 안심하고 실제 파일 시스템의 위치(고정 위치)에 데이터와 메타데이터를 업데이트한다.
- Free: 체크포인트가 끝나면 저널 내의 해당 트랜잭션을 해제하여 공간을 재사용한다.
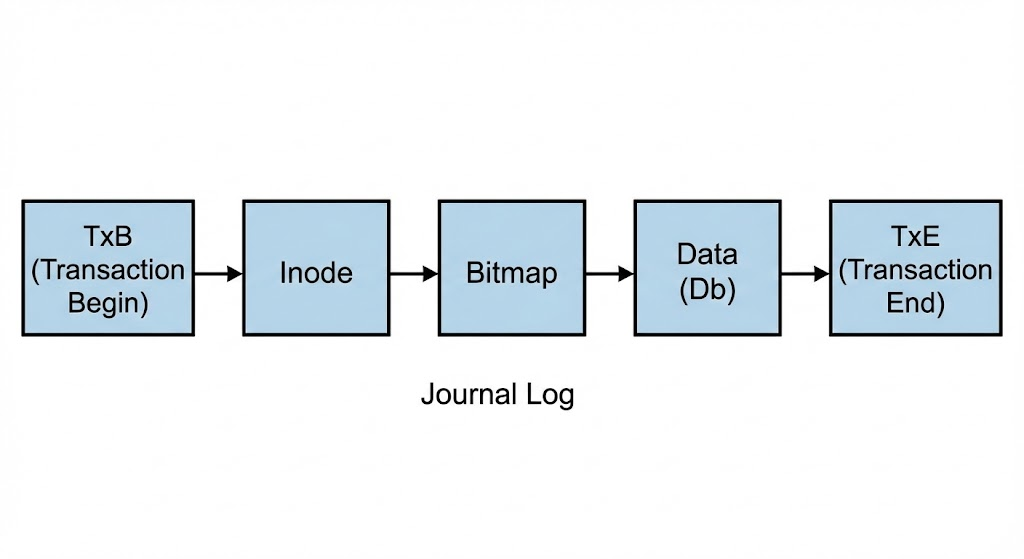
위 이미지는 저널링 로그의 구조를 보여준다. 트랜잭션 시작(TxB)부터 끝(TxE)까지의 기록이 순차적으로 저장되며, 이 기록을 바탕으로 복구가 이루어진다.
4. 성능 최적화: 메타데이터 저널링 (Ordered Journaling)
데이터를 매번 두 번(저널에 한 번, 실제 위치에 한 번) 쓰는 것은 너무 느리다. 그래서 현대의 ext3, ext4는 '메타데이터 저널링' 방식을 주로 사용한다.
Ordered Journaling의 작동 원리
- 데이터 쓰기: 사용자 데이터(Db)를 실제 위치에 먼저 쓴다.
- 메타데이터 저널링: 메타데이터(Inode, Bitmap)만 저널에 기록하고 커밋한다.
- 체크포인트: 메타데이터를 실제 위치에 업데이트한다.
왜 이 순서인가? 데이터를 먼저 쓰고 메타데이터를 나중에 저널링함으로써, 메타데이터가 업데이트되었을 때 해당 포인터가 이미 유효한 데이터를 가리키고 있음을 보장한다. 만약 데이터 쓰기 도중 충돌하면 메타데이터는 저널에 기록되지 않으므로 시스템 일관성은 완벽하게 유지된다.
5. 요약: 복구 메커니즘
충돌 후 재부팅 시 시스템은 저널을 살핀다.
- TxB는 있는데 TxE가 없다면?: 트랜잭션이 불완전하므로 해당 로그는 무시한다.
- TxE까지 완벽하게 기록되어 있다면?: 체크포인트 도중 충돌한 것이므로 저널의 내용을 다시 실제 위치에 덮어쓴다(Redo Log). 이 과정은 전체 디스크 스캔이 필요 없으므로 수 초 내에 끝난다.
이러한 저널링 기법은 파일 시스템의 신뢰성을 획기적으로 높였으며, 오늘날 거의 모든 범용 파일 시스템의 표준이 되었다.
'Deep Dive > OS' 카테고리의 다른 글
| [OSTEP] 스터디 18주차 Flash 기반 SSD (0) | 2025.12.29 |
|---|---|
| [OSTEP] 스터디 17주차 Part.2 Data Integrity and Protection (0) | 2025.12.23 |
| [OSTEP] 스터디 16주차 Fast File System (FFS) 와 로그 구조화 파일 시스템 (LFS) (0) | 2025.12.23 |
| [OSTEP] 스터디 15주차 Part.2 파일 시스템 구현 (0) | 2025.12.09 |
| [OSTEP] 스터디 15주차 Part.1 파일과 디렉터리 (1) | 2025.12.09 |