

6.4 Cache Memories
초기 컴퓨터 시스템의 메모리 계층은 단순했다:
- CPU 레지스터
- 메인 메모리
- 디스크 저장장치
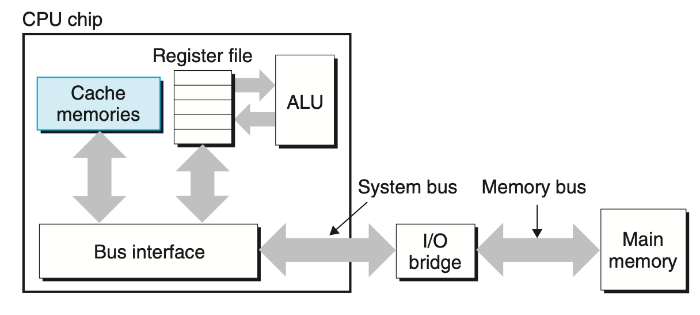
하지만 CPU와 메인 메모리 사이의 성능 격차가 점점 커지면서, 시스템 설계자들은 CPU 레지스터 파일과 메인 메모리 사이에 작은 고속 L1 캐시를 추가하게 되었다.
- L1 캐시: 대개 4 클럭 사이클 안에 접근할 수 있으며, 레지스터에 접근하는 속도와 거의 비슷하다.
- 이후 성능 격차가 더 커지면서 L2 캐시를 L1과 메인 메모리 사이에 추가했고, 이 캐시는 약 10 클럭 사이클 정도로 접근할 수 있다.
- 더 현대 시스템에서는 L3 캐시까지 추가하여, 메인 메모리 접근 전 마지막 캐시 단계로 삼고 있다(약 50 클럭 사이클).
이 장에서는 간단히 CPU와 메인 메모리 사이에 단일 L1 캐시가 있는 시스템을 기준으로 설명한다.
6.4.1 Generic Cache Memory Organization
캐시 메모리는 다음과 같이 조직된다:

- 각 메모리 주소는 m비트로 구성되어 있으며, 총 M=2^m개의 고유 주소를 가진다.
- 캐시는 S=2^s개의 세트(set)로 구성된다.
- 각 세트는 E개의 캐시 라인(line)을 가진다.
- 각 라인은 다음을 포함한다:
- B=2^b 바이트 크기의 데이터 블록
- 유효(valid) 비트: 라인에 유효한 데이터가 있는지 표시
- 태그(tag) 비트: 저장된 블록을 고유하게 식별하는 m-(b+s)비트
따라서, 캐시 구조는 (S, E, B, m)으로 요약할 수 있다.

캐시 용량(C)은 다음과 같이 계산된다:
- C = S × E × B
(단, 유효 비트와 태그 비트 크기는 제외하고 데이터 블록 크기만 포함)
캐시 접근 절차
CPU가 메모리 주소 A에서 데이터를 읽으려 할 때:
- 주소 A를 캐시로 보낸다.
- 캐시는 주소 비트를 분리한다:
- 태그(Tag): 고유 식별자
- 세트 인덱스(Set Index): 어떤 세트를 조회할지 결정
- 블록 오프셋(Block Offset): 블록 내에서 데이터의 위치
- 세트 인덱스를 이용해 세트를 찾고,
- 태그를 비교해 적절한 캐시 라인을 찾은 후,
- 블록 오프셋으로 필요한 바이트를 가져온다.
이는 해시 테이블을 사용하는 것과 비슷하게 동작하며, 매우 단순한 해시 함수를 적용하는 형태다.
6.4.2 직접 매핑 캐시 (Direct-Mapped Caches)
직접 매핑 캐시란 각 세트에 정확히 하나의 라인만 있는 캐시를 의미한다. 즉, E = 1인 경우를 말한다.
직접 매핑 캐시는 구현이 가장 쉽고, 이해하기도 간단하기 때문에 캐시 작동 원리를 설명할 때 주로 사용된다.
직접 매핑 캐시의 동작 과정
CPU가 메모리 워드 w를 읽고자 할 때 다음과 같은 절차를 따른다:

- 세트 선택(Set Selection)
- 주소 A에서 세트 인덱스(set index) 비트를 추출하여, 어떤 세트를 조회할지 결정한다.
- 세트 인덱스는 주소 비트 중간에 위치한다.
- 라인 매칭(Line Matching)
- 선택된 세트에 저장된 캐시 라인의 태그(tag)와 주소 A의 태그를 비교한다.
- 유효(valid) 비트가 1이고, 태그가 일치하면 캐시 히트(hit)이다.
- 둘 중 하나라도 일치하지 않으면 캐시 미스(miss)이다.
- 워드 추출(Word Extraction)
- 블록 오프셋(block offset) 비트를 사용하여 원하는 워드를 블록 내에서 찾아 읽는다.
미스 발생 시 라인 교체(Line Replacement)
- 만약 미스가 발생하면, 캐시는 메인 메모리(또는 하위 캐시)로부터 블록을 가져와 현재 세트의 기존 라인을 덮어쓴다.
- 직접 매핑 캐시는 세트당 라인이 하나뿐이므로, 교체 정책은 매우 단순하다: 무조건 교체한다.
예시
- (S, E, B, m) = (4, 1, 2, 4)인 캐시를 가정하자.
- 세트 수(S) = 4
- 세트당 라인 수(E) = 1
- 블록 크기(B) = 2바이트
- 주소 비트 수(m) = 4비트
이 경우:
- 4개의 세트가 있고,
- 각 세트는 하나의 라인만 가진다,
- 블록은 2바이트로, 블록 오프셋은 1비트가 필요하다,
- 세트 인덱스는 2비트로 표현된다.
주소의 태그 비트, 세트 인덱스 비트, 블록 오프셋 비트로 나누어 캐시 탐색이 이루어진다.
Conflict Misses 문제
- 서로 다른 메모리 블록이 같은 세트에 매핑되면 충돌(conflict)이 발생할 수 있다.
- 이로 인해 충분히 캐시 용량이 있어도 미스가 반복적으로 발생하는 현상이 생긴다.
6.4.3 집합 연결 캐시 (Set Associative Caches)
문제
직접 매핑 캐시는 각 세트가 오직 하나의 캐시 라인만 가지기 때문에 충돌 미스(conflict miss)가 쉽게 발생한다.
해결책
집합 연결 캐시는 이 제약을 완화하여, 각 세트가 여러 개의 캐시 라인(1 < E < C/B)을 갖도록 한다.
- 이를 E-웨이 집합 연결 캐시(E-way Set Associative Cache)라고 부른다.

집합 연결 캐시 구조
- 각 세트는 E개의 라인을 가진다.
- 각 라인은 Valid, Tag, Cache Block 필드를 가진다.
- 예를 들어, 2-웨이 집합 연결 캐시는 세트당 2개의 라인을 갖는다.
세트 선택 (Set Selection)
- 직접 매핑 캐시와 동일하게 세트 인덱스(set index) 비트를 사용하여 세트를 선택한다.
라인 매칭과 워드 선택 (Line Matching and Word Selection)

- 세트 연결 캐시에서는 세트 내 모든 라인의 Valid 비트와 Tag를 검사해야 한다.
- 조건:
- Valid 비트가 1이어야 한다.
- 저장된 Tag가 주소의 Tag와 일치해야 한다.
- 둘 다 만족하는 라인이 있다면 캐시 히트(hit)이고, 블록 오프셋을 사용해 원하는 바이트를 읽는다.
- 일치하는 라인이 없다면 캐시 미스(miss)가 발생한다.
라인 교체 (Line Replacement on Miss)
- 미스가 발생하면 메모리로부터 블록을 가져와야 한다.
- 만약 선택된 세트에 비어 있는(Valid=0) 라인이 있다면, 그 라인에 새 블록을 저장한다.
- 비어 있는 라인이 없다면, 기존 라인 중 하나를 교체(evict) 해야 한다.
교체 정책 (Replacement Policies)
- 랜덤(Random): 무작위로 라인을 선택하여 교체.
- LFU (Least Frequently Used): 가장 적게 참조된 라인을 교체.
- LRU (Least Recently Used): 가장 오래전에 참조된 라인을 교체.
LRU 방식이 일반적으로 가장 많이 사용된다.
이러한 정책들은 추가적인 하드웨어와 시간이 필요하지만, 미스율을 낮추는 데 효과적이다.
집합 연결 캐시 요약
| 항목 | 설명 |
| 세트당 라인 수 | 1 < E < C/B |
| 장점 | 충돌 미스를 줄여줌 |
| 단점 | 라인 검색 비용 증가 |
| 캐시 접근 시 | 세트 내 모든 라인 검사 |
| 미스 발생 시 | 비어 있는 라인 또는 교체 정책 이용 |
6.4.4 완전 연결 캐시 (Fully Associative Caches)
개념
완전 연결 캐시는 오직 하나의 세트만을 가진다. 즉, 모든 캐시 라인이 하나의 세트에 속한다.
- 세트 수 S = 1
- 세트당 라인 수 E = C/B (캐시 용량 C를 블록 크기 B로 나눈 값)
결국 전체 캐시가 하나의 거대한 세트로 동작한다.
완전 연결 캐시의 구조
구성은 다음과 같다:
- Valid 비트: 해당 라인이 유효한지 표시
- Tag 비트: 메모리 주소의 상위 비트 일부를 저장
- Cache Block: 메모리 블록 데이터를 저장
세트 선택 (Set Selection)
- 항상 세트 0을 선택한다.
- 세트 인덱스가 필요 없으므로, 주소는 Tag + Block Offset으로만 구성된다.
라인 매칭과 워드 선택 (Line Matching and Word Selection)
CPU가 메모리 주소 A를 요청하면 다음 과정을 따른다:
- 모든 라인 검색:
- 각 라인의 Valid 비트가 1인지 확인.
- 저장된 Tag가 주소 A의 Tag와 일치하는지 검사.
- 히트(hit) 발생 시:
- 블록 오프셋을 사용하여 필요한 워드를 블록 내에서 선택.
- 미스(miss) 발생 시:
- 메인 메모리에서 블록을 읽어와 캐시에 저장하고, 교체할 라인을 선택하여 덮어쓴다.
특징과 한계
- 장점:
- 어떤 메모리 블록도 캐시 내 아무 라인에나 저장할 수 있으므로, 충돌 미스(conflict miss)가 없다.
- 단점:
- 모든 라인을 병렬로 검색해야 하므로, 하드웨어 구현이 복잡하고 비싸다.
- 규모가 큰 완전 연결 캐시는 매우 느리고 비효율적이기 때문에, 일반적으로 작은 캐시에만 사용된다.
대표적 사용 예:
- 가상 메모리 시스템의 TLB(Translation Lookaside Buffer)는 완전 연결 캐시를 사용한다.
6.4.5 쓰기 연산과 관련된 문제들 (Issues with Writes)
기(Read) 연산은 캐시 동작이 단순하다:
- 캐시에 원하는 워드 w가 있으면 즉시 반환한다 (히트).
- 없으면 하위 메모리 계층에서 블록을 가져와 캐시에 저장한 후 반환한다.
반면, 쓰기(Write) 연산은 더 복잡하다.
쓰기 히트 (Write Hit)
만약 CPU가 이미 캐시에 존재하는 워드 w를 수정(write)한다면,
- 캐시는 자신의 복사본을 업데이트한다.
- 문제: 하위 계층 메모리(ex. 메인 메모리)도 즉시 업데이트해야 할까?
이를 해결하는 두 가지 주요 정책이 있다:
- Write-Through (즉시 기록)
- 캐시에서 w를 수정한 즉시 하위 계층에도 똑같이 반영한다.
- 장점: 단순하다.
- 단점: 모든 쓰기가 버스 트래픽을 유발하여 비효율적이다.
- Write-Back (지연 기록)
- 캐시에서만 수정하고, 블록이 캐시에서 **교체(evict)**될 때 하위 계층에 기록한다.
- 장점: 쓰기 횟수를 줄여 버스 트래픽을 크게 줄인다.
- 단점: 구현이 복잡하다 (Dirty bit 관리 필요).
- Dirty Bit: 해당 캐시 라인이 수정되었는지를 나타내는 추가 비트.
쓰기 미스 (Write Miss)
캐시에 워드 w가 없는 경우, 두 가지 접근법이 있다:
- Write-Allocate (캐시 적재 후 쓰기)
- 미스 발생 시, 하위 계층에서 해당 블록을 읽어와 캐시에 적재한 다음 워드를 수정한다.
- 공간적 지역성을 활용할 수 있다.
- 단점: 모든 쓰기 미스마다 블록 전송 비용 발생.
- No-Write-Allocate (직접 하위 계층에 쓰기)
- 캐시에 적재하지 않고 하위 계층에 직접 쓰기만 한다.
- 주로 Write-Through 캐시에서 사용된다.
Write-Back 캐시는 보통 Write-Allocate 방식을 채택한다.
최적화와 현실
- 쓰기를 최적화하는 것은 매우 까다롭고 시스템마다 세부사항이 다르다.
- 보통 프로그래머는 "Write-Back + Write-Allocate" 캐시 모델을 가정하고 코딩하는 것이 좋다.
- 이는 최신 시스템 트렌드와도 일치한다:
- 하위 계층일수록 Write-Back 방식을 사용한다 (ex. 가상 메모리 시스템).
- 논리 집적도가 증가하면서 Write-Back 복잡성이 더 이상 큰 문제가 아니다.
- Write-Back/Write-Allocate는 읽기 최적화 전략과 대칭적이어서 지역성(locality)을 극대화하는 데 유리하다.
6.4.6 실제 캐시 계층 구조 해부 (Anatomy of a Real Cache Hierarchy)
지금까지 설명했던 캐시는 프로그램 데이터만 저장한다고 가정했다. 하지만 실제로 캐시는 명령어(instruction)와 데이터(data) 둘 다 저장할 수 있다.
캐시의 종류는 다음과 같다:
- i-cache (Instruction Cache): 명령어만 저장하는 캐시
- d-cache (Data Cache): 프로그램 데이터만 저장하는 캐시
- 통합 캐시 (Unified Cache): 명령어와 데이터를 함께 저장하는 캐시
i-cache와 d-cache를 구분하는 이유
현대 프로세서는 i-cache와 d-cache를 별도로 가지고 있다. 이렇게 나누는 이유는 다음과 같다:
- 명령어와 데이터를 동시에 읽을 수 있다 (병렬 처리 가능).
- 명령어는 보통 읽기 전용이기 때문에 i-cache는 더 단순하게 만들 수 있다.
- i-cache와 d-cache는 서로 다른 접근 패턴에 맞춰 최적화할 수 있다.
- 블록 크기(block size)
- 연결도(associativity)
- 용량(capacity) 등이 다를 수 있다.
- 명령어 접근과 데이터 접근 간 충돌 미스(conflict miss)를 방지할 수 있다.
단점: i-cache와 d-cache를 분리하면 가끔 용량 미스(capacity miss)가 증가할 수 있다.
Intel Core i7 캐시 계층 구조 예시
Intel Core i7 프로세서의 캐시 구조는 다음과 같다:
- 각 CPU 칩은 4개의 코어를 가진다.
- 각 코어는 개인용으로 다음을 가진다:
- L1 i-cache (명령어 캐시)
- L1 d-cache (데이터 캐시)
- L2 통합 캐시 (명령어 + 데이터)
- 모든 코어는 하나의 공유 L3 통합 캐시를 사용한다.
특이사항:
- 모든 SRAM 기반 캐시는 CPU 칩 안에 통합되어 있다.
Core i7 캐시 특성 요약 (표)
| 캐시 종류 | 접근 시간 (클럭 사이클) | 용량(C) | 연결도(E) | 블록 크기(B) | 세트 수 (S) |
| L1 i-cache | 4 | 32 KB | 8 | 64 B | 64 |
| L1 d-cache | 4 | 32 KB | 8 | 64 B | 64 |
| L2 통합 캐시 | 10 | 256 KB | 8 | 64 B | 512 |
| L3 통합 캐시 (공유) | 40~75 | 8 MB | 16 | 64 B | 8,192 |
6.4.7 캐시 파라미터가 성능에 미치는 영향 (Performance Impact of Cache Parameters)
캐시 성능은 여러 가지 지표로 평가할 수 있다:
- Miss Rate (미스율)
프로그램 실행 중 발생하는 메모리 참조 중에서 미스를 차지하는 비율.
계산: 미스 수 / 참조 수 - Hit Rate (히트율)
전체 메모리 참조 중 히트가 발생하는 비율.
계산: 1 - 미스율 - Hit Time (히트 시간)
캐시에서 워드를 CPU로 전달하는 데 걸리는 시간.
(세트 선택, 라인 식별, 워드 선택을 포함)
L1 캐시의 경우 보통 수 클럭 사이클 내에 완료된다. - Miss Penalty (미스 페널티)
미스가 발생했을 때 추가로 소요되는 시간.
(예: L1 미스는 L2에서 10 클럭, L3에서 50 클럭, 메인 메모리에서는 200 클럭 정도)
캐시 크기(Cache Size)의 영향
- 크기가 큰 캐시는 히트율을 증가시킨다. 더 많은 데이터를 저장할 수 있기 때문이다.
- 하지만 메모리가 클수록 느려지는 경향이 있다. 큰 캐시는 액세스 시간이 길어져 히트 시간이 증가한다.
- 그래서 L1 캐시가 L2 캐시보다 작고, L2가 L3보다 작은 이유가 여기에 있다.
블록 크기(Block Size)의 영향
- 블록 크기가 커지면 공간적 지역성을 더 잘 활용할 수 있어 히트율이 증가할 수 있다.
- 하지만 일정 캐시 크기에서 블록 크기를 키우면, 저장할 수 있는 블록 수(라인 수)가 줄어들어 시간적 지역성이 좋은 프로그램에서는 오히려 히트율이 떨어질 수 있다.
- 또한 블록 크기가 크면 미스 페널티도 커진다(블록 하나를 전송하는 데 더 많은 시간이 걸림).
- Core i7 시스템은 보통 64바이트 블록을 사용하여 이 균형을 잡는다.
연결도(Associativity)의 영향
- 연결도(E)는 세트당 캐시 라인 수를 뜻한다.
- 연결도가 높으면 충돌 미스(conflict miss) 확률이 줄어든다.
- 하지만 높은 연결도는 단점도 있다:
- 구현 복잡도 증가 (더 많은 태그 비교, 추가 LRU 상태 관리 필요)
- 히트 시간이 증가할 수 있다.
- 미스 페널티도 약간 증가할 수 있다.
결론:
- L1 캐시는 보통 낮은 연결도(빠른 접근을 위해)를 선택하고,
- L2, L3처럼 미스 페널티가 큰 하위 캐시들은 높은 연결도를 선택한다.
예: Core i7은 L1과 L2가 8-way 연결, L3가 16-way 연결이다.
쓰기 전략(Write Strategy)의 영향
- Write-Through 캐시:
- 구현이 간단하다.
- 쓰기 버퍼를 사용해 캐시와 독립적으로 메모리를 갱신할 수 있다.
- 읽기 미스가 간단해진다 (쓰기 때문에 기다릴 필요 없음).
- Write-Back 캐시:
- 메모리로의 전송 횟수를 줄여준다.
- 특히 I/O 디바이스와의 대역폭 충돌을 줄이는 데 유리하다.
- 계층이 낮아질수록(메모리 접근 비용이 클수록) Write-Back을 선호하게 된다.
'크래프톤 정글 (컴퓨터 시스템: CSAPP) > 6장 메모리 계층구조' 카테고리의 다른 글
| 컴퓨터 시스템 : CSAPP 6장 정리 - 종합: 프로그램 성능에 대한 캐시의 영향 (2) | 2025.04.28 |
|---|---|
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.5 캐시 친화적 코드 작성 (0) | 2025.04.28 |
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.3 메모리 계층 구조 (0) | 2025.04.28 |
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.2 지역성 (0) | 2025.04.28 |
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.1 저장장치 기술 (1) | 2025.04.28 |