

6.6 캐시가 프로그램 성능에 미치는 영향 (Putting It Together: The Impact of Caches on Program Performance)
지금까지 메모리 계층 구조를 살펴봤다. 이번 절에서는 캐시가 실제 머신에서 프로그램 성능에 어떤 영향을 미치는지를 살펴본다.
- 메모리 계층 구조는 프로그램 성능에 지대한 영향을 미친다.
- 특히, 프로그램이 메모리 시스템에서 데이터를 읽어 들이는 속도(읽기 처리량, read throughput)가 중요한 성능 지표가 된다.
- 지역성(locality)을 잘 활용하면 프로그램이 훨씬 빠르게 동작할 수 있다.
6.6.1 메모리 마운틴 (The Memory Mountain)
개념
- 프로그램이 메모리 시스템으로부터 데이터를 읽어들이는 속도를 읽기 처리량(read throughput) 또는 읽기 대역폭(read bandwidth)라고 부른다.
- n바이트를 s초 동안 읽었다면, 읽기 처리량은 n/s이며, 보통 MB/s(메가바이트/초) 단위로 표현한다.
실험 방법
- 특정 읽기 패턴을 가진 프로그램을 작성하여, 루프 안에서 읽기 요청을 연속으로 발생시킨다.
- 이때의 읽기 처리량을 측정하면 메모리 시스템의 성능에 대한 중요한 통찰을 얻을 수 있다.
테스트 함수 설명
- test 함수: 주어진 stride(건너뛰기 간격)로 배열을 순회하며 데이터를 읽는다.
- 루프 언롤링(loop unrolling) 4 ×4 기법을 적용해 병렬성을 높였다.
- run 함수: test를 호출하여 읽기 처리량을 측정하고 반환한다.
실험 매개변수: size와 stride
- size는 배열에서 사용할 데이터의 총 크기를 의미한다(바이트 단위).
- stride는 읽을 때마다 몇 개 요소를 건너뛸지를 결정한다.
- 작은 size → 작업 집합(working set)이 작아져 시간적 지역성이 좋아진다.
- 작은 stride → 인접 데이터 접근이 많아져 공간적 지역성이 좋아진다.
메모리 마운틴(Memory Mountain)이란?
- size와 stride를 다양하게 조정해가며 읽기 처리량을 측정하면,
읽기 처리량 vs 시간적/공간적 지역성을 2차원 함수 형태로 나타낼 수 있다. - 이 2차원 지형을 "메모리 마운틴"이라고 부른다.
특징
- 컴퓨터마다 고유한 메모리 마운틴을 가진다.
- 예를 들어 Intel Core i7 Haswell 시스템은 size를 16KB~128MB 범위로, stride를 112요소 범위로 설정하여 실험한다.
메모리 마운틴 해석 예시
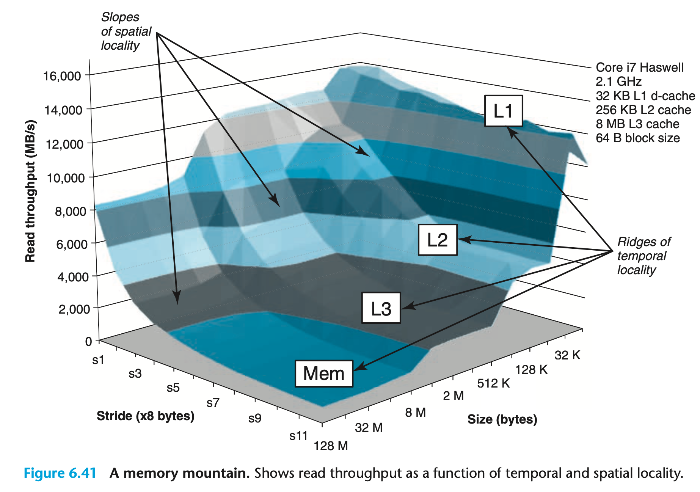
- Core i7 시스템에서 보면:
- L1 캐시 영역에서는 읽기 처리량이 14GB/s 이상이다.
- 메인 메모리 영역에서는 처리량이 900MB/s까지 감소한다.
- stride가 커질수록 공간적 지역성이 나빠져 처리량이 줄어든다.
- stride=1일 때는 하드웨어 프리페칭(prefetching) 덕분에 처리량이 일정하게 유지되는 현상도 관찰된다.
6.6.2 공간적 지역성 향상을 위한 루프 재배열 (Rearranging Loops to Increase Spatial Locality)
문제
n × n 행렬 A와 B를 곱해서 결과를 C에 저장하는 행렬 곱셈 문제를 생각해본다.
예를 들어, n=2일 경우:

그리고 곱셈 식은 다음과 같다:

기본 구현
행렬 곱셈은 보통 i, j, k 세 개의 중첩 루프(nested loops)를 사용하여 작성된다.
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
for (k = 0; k < n; k++)
C[i][j] += A[i][k] * B[k][j];루프 순서 변경
- 루프의 순서를 바꾸고 약간의 코드 수정만 해도, 기능적으로 동일한 6가지 버전을 만들 수 있다.
- 각각은 루프의 순서를 어떻게 정했는지(ijk, jik, kij, ikj, jki, kji)로 구별된다.
공통점:
- 모든 버전은 O(n³)번의 연산을 수행한다.
- 각각 n²개의 요소를 n번 읽는다.
- 각 C 요소는 n개의 값의 합으로 계산된다.
차이점:
- 내부 루프(inner loop)에서 메모리 접근 패턴이 다르고, 그에 따라 캐시 미스 수가 다르다.
- 그래서 성능 차이가 발생한다.
분석 가정
분석을 단순화하기 위해 다음을 가정한다:
- 배열은 n×n 크기의 double 타입 배열이다 (각 double은 8바이트).
- 캐시 블록 크기는 32바이트다 (B=32).
- n이 충분히 커서 한 행 전체가 L1 캐시에 안 들어간다.
- 컴파일러는 지역 변수는 레지스터에 저장한다(즉, i, j, k 접근은 별도 메모리 접근을 필요로 하지 않는다).
결과 요약
내부 루프 분석 결과:
- 6개 버전은 3개 클래스로 나뉜다.
- AB 클래스: A와 B를 내부 루프에서 참조 (ijk, jik)
- AC 클래스: A와 C를 참조 (ikj, kij)
- BC 클래스: B와 C를 참조 (jki, kji)
각 클래스에 대해:
- 내부 루프에서 읽기(load)와 쓰기(store) 수,
- 캐시 미스 수를 계산했다.
주요 관찰:
- AB 버전은 매 루프마다 두 번 로드를 하지만 공간적 지역성이 나빠 많은 캐시 미스를 낸다.
- BC 버전은 두 번 로드하고 한 번 저장하지만, stride-1 접근 덕분에 캐시 미스가 적다.
핵심 요점
- 연산량(덧셈, 곱셈) 자체는 같지만, 메모리 접근 패턴에 따라 성능 차이가 최대 40배까지 발생할 수 있다.
- 캐시 미스율이 낮은 버전이 항상 더 빠르다.
- 공간적 지역성(spatial locality)을 잘 살리면 캐시 미스를 줄이고 성능을 크게 높일 수 있다.
6.6.3 프로그램에서 지역성 활용하기 (Exploiting Locality in Your Programs)
기본개념
지금까지 살펴봤듯이, 메모리 시스템은 크기, 비용, 접근 시간이 다른 다양한 저장 장치로 구성된 계층 구조를 이룬다.
- 상위 계층은 작고 빠른 저장 장치(예: L1 캐시)
- 하위 계층은 크고 느린 저장 장치(예: 디스크 드라이브)
이러한 구조 덕분에 프로그램이 메모리 위치를 접근하는 실제 속도는 하나의 수치로 표현할 수 없다.
속도는 프로그램이 얼마나 좋은 지역성(locality)을 가지느냐에 따라 크게 달라진다.
결론:
- 좋은 지역성을 가진 프로그램은 대부분의 데이터를 빠른 캐시 메모리에서 읽어온다.
- 나쁜 지역성을 가진 프로그램은 대부분의 데이터를 느린 메인 메모리(DRAM)에서 읽어오게 된다.
프로그래머가 취할 전략
메모리 계층 구조의 본질을 이해하면, 특정 하드웨어 시스템에 상관없이 효율적인 프로그램을 작성할 수 있다.
특히 다음 기술들을 추천한다:
- 내부 루프(inner loops)에 집중하라
대부분의 연산과 메모리 접근은 내부 루프에서 발생한다. - 공간적 지역성(spatial locality)을 극대화하라
메모리에 저장된 순서대로 데이터를 순차적으로 읽어라.
즉, stride-1 접근을 사용해라. - 시간적 지역성(temporal locality)을 극대화하라
메모리에서 데이터를 읽어온 뒤에는 그 데이터를 가능한 한 많이 재사용하라.
'크래프톤 정글 (컴퓨터 시스템: CSAPP) > 6장 메모리 계층구조' 카테고리의 다른 글
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.5 캐시 친화적 코드 작성 (0) | 2025.04.28 |
|---|---|
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.4 캐시 메모리 (0) | 2025.04.28 |
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.3 메모리 계층 구조 (0) | 2025.04.28 |
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.2 지역성 (0) | 2025.04.28 |
| 컴퓨터 시스템 : CSAPP 6장 정리 - 6.1 저장장치 기술 (1) | 2025.04.28 |